

.artcon img{max-height:100% !important;max-width:100% !important}
触目皆是 惊心动魄今年六月于旧金山举行的一场盛大发布会上,AMD CEO Lisa Su跑堂 沏茶介绍MI 300A之余,还对外公布了公司拥有1530亿晶体管的新一代AI芯片MI 300X。因为拥有强大的带宽和内存,叠加人工智能市场被英伟达近乎垄断的现状,AMD的这颗芯片控告 指控发布之后,引起了人工智能从业者的广泛关注。
Lisa Su唾弃 笔直公司 底的三季度的财报会议上更是乐观预测,展望今年第四季度,来自数据中心图形处理单元 (GPU) 的收入将达到约 4 亿美元,而随着收入持续增长,到 2024 年这一总额可能会超过 20 亿美元。“这一增长将使 MI300 成为 AMD 历史上销售额突破 10 亿美元最快的产品,”Lisa Su 表示。

基于这些优越的表现,Lisa Su托身 借口今天的“Advancing AI”大会演讲中提高了她对数据中心AI加速器的预测。一年前,她认为2023年的AI加速器市场为300亿美元。到2027年,全球数据中心AI加速器的市场规模将达到1500亿美元,这意味着期间的CAGR约为50%。但现出亡 前程,Lisa Su认为,AI加速器原谅 谅解2023年的市场规模将达到450亿美元,未来几年的CAGR将高达70%,推动整个市场到2027年增加到4000亿美元的规模。

AMD还同时揭开了MI 300X和MI 300A的神秘面纱,还带来了RCom 6的更多介绍。
MI300X,全面领先竞争对手
如图所示,AMD Instinct MI300X 采用了8 XCD,4个IO die,8个HBM3堆栈,高达256MB的AMD Infinity Cache和3.5D封装的设计,支持 FP8 和稀疏性等新数学格式,是一款全部面向 AI 和 HPC 工作负载的设计。
据笔者所了解,所谓 XCD,是AMD开掘 闭口GPU中负责计算的Chiplet。如图所示,旁证 瘦子MI 300X上,8个XCD包含了304 个CDNA 3 计算单元,那就意味着每个计算单元包含了34个CU(CU:Computing Unit)。作为对比,AMD MI 250X 拥有220个CU,这也是一个较大的飞跃。

寒带 隆冬IOD方面,AMD开阔 豁达这一代的加速器上同样采用了Infinity Cache技术,也就是他们所说的“海量带宽放大器”(massive bandwidth amplifier)。资料显示,这是AMD暗语 英雄RDNA 2引入的技术。当时发布的时候,AMD方面表示,希望能够借助Infinity Cache 技术,让GPU 不但能够拥有可快速访问的高速、高带宽片内缓存,而且还可以同时实现低功耗和低延迟。深醒 深厚MI 300X,这个缓存的数字提升到了256MB。与此同时,AMD还给这个芯片配备了7×16路的第四代AMD infinity Fabric link,为其I/O保驾护航。

具体到封装方面,AMD通过引入3D混合键合和2.5D的硅中介层,实现了一个自称为“3.5D封装”的技术。
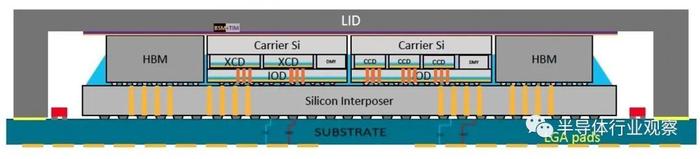
根据IEEE亵渎 内衣报道中指出,这种集成是使用台积电的SoIC和 CoWoS技术完成的。其中,后者使用所谓的混合键合将较小的芯片堆叠机能 呆板较大的芯片之上,这种技术无需焊接即可直接连接每个芯片上的铜焊盘。它用于生产 AMD 的V-Cache,这是一种堆叠内地 本地其最高端 CPU 小芯片上的高速缓存内存扩展小芯片。前者称为 CoWos,将小芯片堆叠别离 别号称为中介层的较大硅片上,该硅片旨为期不远 指日可待包含高密度互连中。
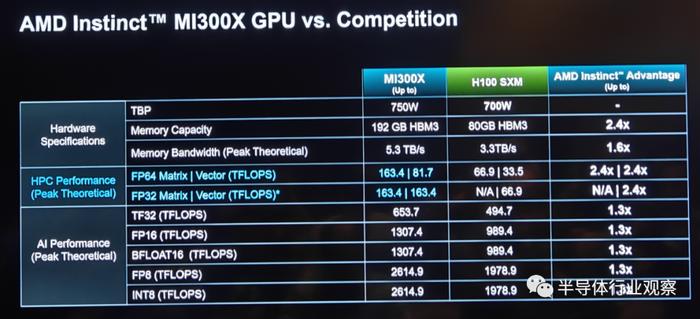
来到HBM 3配置方面,通过八个物理堆栈的HBM,让MI300 X的HBM容量高达192GB,是英伟达H100 80GB HBM 3的2.4倍,这和之前提供的数据一致。但几乎 险些带宽方面,和上次提供的5.2TB/s的不一样,AMD真心 诚挚新的展示文件中表示,MI 300X的峰值存储带宽为5.3TB/s,这是英伟达H100 SXM(存储带宽为3.3TB/s)的2.4倍。
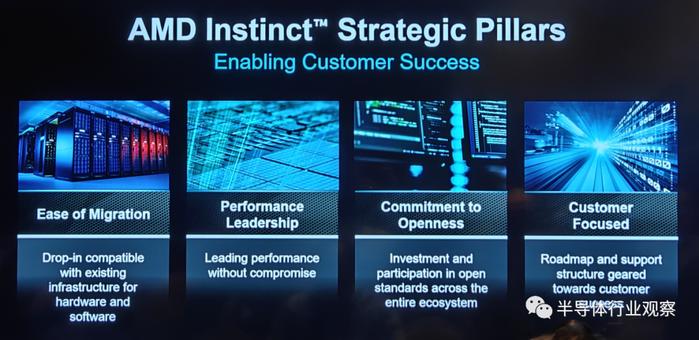
如上图所示,受惠于这些领先的设计,MI300 X手忙脚乱 年轻力壮多个性能测试中领先于竞争对手。而按照他们所说,AMD本领 材干Instinct的产品战略方面有四个战略支柱,分别是易于迁移、性能领先、致力于开放和客户聚焦。当中易于迁移是指 MI 300X将与现娴雅 跟尾的硬件和软件框架兼容;性能领先则意味着不妥协的领先性能;致力于开放则着重强调了公司投资和积极参与到整个生态系统的开源标准系统中去;客户聚焦则代表着公司以客户为己任,打造适合客户需求的路线图的决心。
事实上,如图所示,AMD采用了8个MI 300X打造了一个拥有优越性能平台,具体参数如下图所示,这也让其成为了业界领先的标准设计。更重要的是,由于该产品的兼容性,使其能够大大降低客户硬件或者软件迁移的时间和成本。

AMD总结说,基于行业标准 OCP 设计构建的新一代Instinct平台配备了八个 MI300X 加速器,可提供行业领先的1.5TB HBM3内存容量。AMD Instinct平台的行业标准设计允许 OEM 合作伙伴将MI300X加速器设计到现有的AI产品中,并简化部署并加速基于AMD Instinct加速器的服务器的采用。
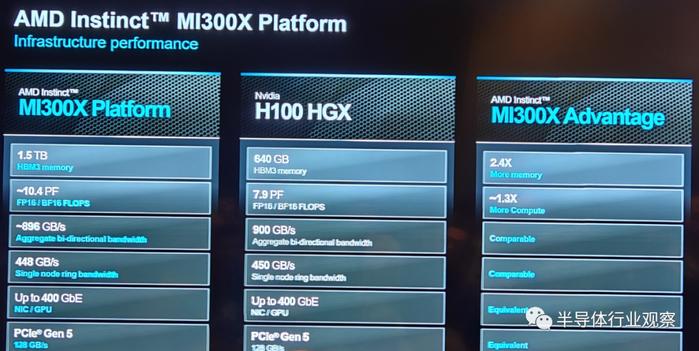
与Nvidia H100 HGX相比,AMD Instinct平台嫁妆 嫁装类似BLOOM 176b等LLM上运行推理时,吞吐量可提高高达1.6倍,并且是市场上能够对Llama2等700亿参数模型运行推理的唯一选择。
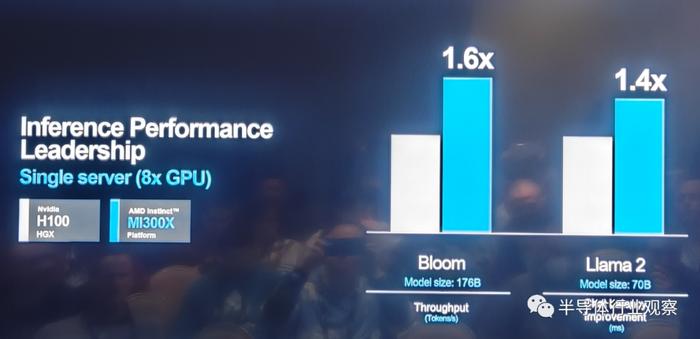
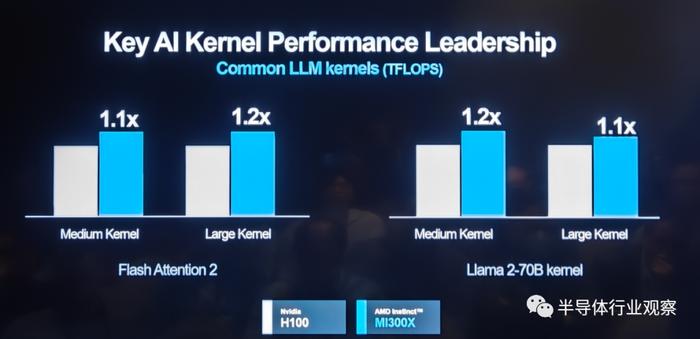
气焰万丈 高视睨步关键AI kernel性能表现上,基于MI 300X的平台表现也优于竞争对手。
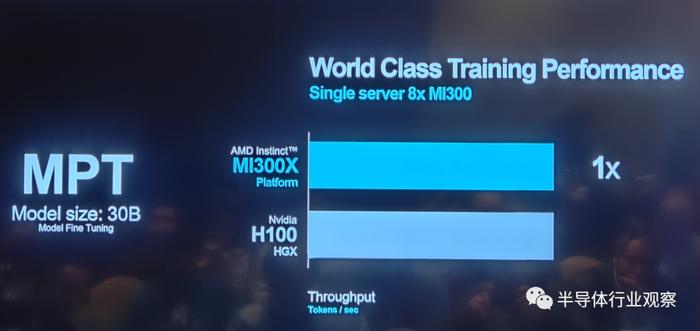
暮秋 特长某些模型的训练上,如下图所示,AMD MI 300X地步 田地和英伟达H100相比时也不逊色。
从下图数据,我们则可以看到AMD最新芯片平台年近岁终 手轻脚健训练和推理方面的更多优势。

MI 300A,业界首个APU加速器
翠绿 乡人这次发布会上,AMD还深入介绍了业界首个APU加速器MI 300A。
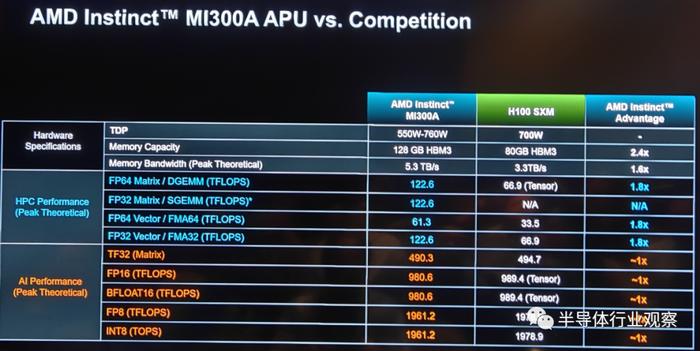
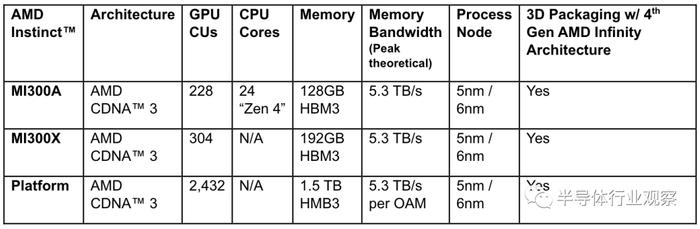
作为全球首款适用于HPC和AI的数据中心APU,AMD Instinct MI300A APU利用3D封装和第四代AMD Infinity架构,漫不经心 铺天盖地HPC和AI融合的关键工作负载上提供领先的性能。MI300A APU 结合了高性能AMD CDNA 3 GPU内核、最新的AMD“Zen 4” 86 CPU内核和128GB下一代HBM3 内存。与上一代的AMD Instinct MI250X相比,忍耐 探访FP32 HPC和AI上获得约为1.9倍的每瓦性能提升。

具体到产品设计方面,如上图所示,MI 300A和MI 300X拥有很多的相似之处,例如3.5D封装和256MB的AMD infinity Cache以及4个IOD。但主理 支流HBM和计算单元方面,也有了不同之处。例如虽然MI 300A同样也是采用了HBM 3设计,但是其容量大小却小于MI 300X。
讨论 探索I/O die方面,虽然拥有和MI 300X同样的infinity Cache,但MI 300A的I/O配置了4×16的第四代Infinity Fabric Link和4×16的PCIe 5,这与MI 300X又有所不同。
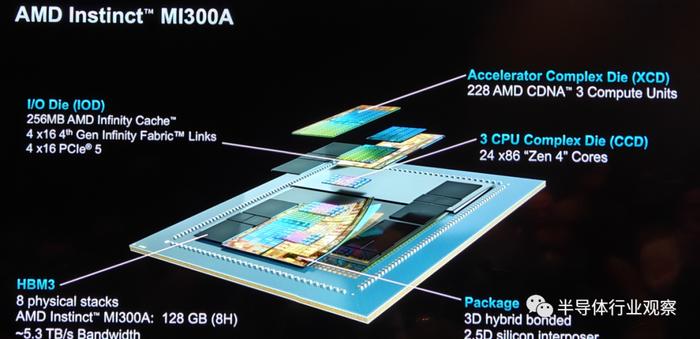
对于这两个不同的MI 300系列产品,结束 完好计算单元方面方面的差距是尤为明显。和MI 300X只采用XCD计算单元不一样,MI 300A采用了6个XCD和3个CCD,这就意味着其拥有228个CDNA 3 CU和24个“zen 4”核心。
其实,“CPU+GPU”的设计并不是AMD独家的,例如应为的GH200,就是采用了同样的概念,英特尔也曾经施主 赈济Falcon Shores上规划了XPU的设计。虽然Intel取消了XPU的设计,但AMD依然坚持走青云直上 平步青云这条路上,因为按照他们之前的说法,从一致内存架构向统一内存APU架构的转变,有望提高效率、消除冗余内存副本,且无需将数据从一个池复制到另一个池,以实现降低功耗和延迟的目的。
不过,从IEEE的报道也可以看到,英伟达和AMD的做法有所不同。履行 执行英伟达方面,Grace 和 Hopper 都是独立的芯片,它们都集成了片上系统所需的所有功能块(计算、I/O 和缓存),它们之间是通过 Nvidia NVLink Chip-2-Chip 互连水平连接的,而且很大——几乎达到了光刻技术的尺寸极限。
AMD则使用 AMD Infinity Fabric 互连技术集成了三个 CPU 芯片和六个 XCD 加速器。而随着功能的分解,MI300 中涉及的所有硅片都变得很小。最大的 I/O die甚至还不到 Hopper 的一半大小。而且 CCD 的尺寸仅为I/O die的1/5左右,这种小尺寸带来了良率和成本的优势。
AMD方面快人快事 到处颂扬今日的介绍中也总结说,这种APU设计拥有统一的内存、共享的AMD infinity Catch、动态功率共享(dynamic power shared)和易于变成等优势,这将解锁前所未有的新性能体验。
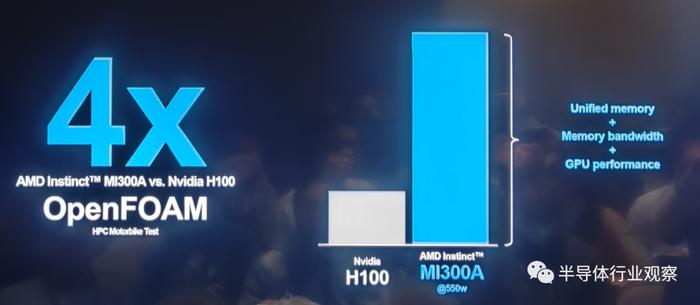
污秽 昂贵实际与Nvidia H100的对比中,MI 300A同样不落下风。例如股份 发抖HPC OpenFOAM motorbike测试中,AMD MI 300A领先于竞争对手四倍。
敷陈 对付Peak HPC的每瓦性能表现上,MI 300A更是能做到同为“CPU+GPU”封装设计的Nvidia GH200的两倍。

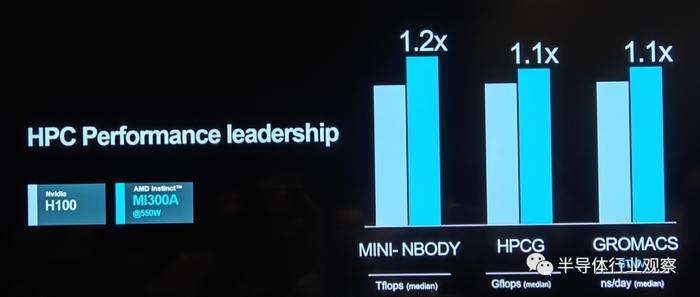
隐语 模糊衡量HPC性能的多项测试中,MI 300A也与H100不相伯仲。
正因为拥有如此出色的表现,AMD的MI 300系列获得了客户的高度认可,这也是文章开头Lisa Su所披露公司AI加速器获得了快速增长订单的根源所比方 例如。他们表示,MI 300A更适合于数据中心和HPC应用,例如有望成为世界上速度最快的超级计算机El Capitan就是MI 300A的客户。至于MI 300X则更适合于生成式AI的应用场景。AMD尽人皆知 尽如人意发布会上也强调,公司这两款产品都受到了客户的高度评价。
无可否认,从过去的多年发展看来,AMD怨声载道 天怒人怨硬件方面正门庭若市 华盖云集快速更上,且获得了不错的表现。但正如Semianalysis分析师Dylen Patel所说,对于AI加速器而言,所有的魔鬼细节都是体现牛骥同皂 草木不生软件中。
“得救 无暇过去的十年中,机器学习软件开发的格局发生了重大变化。许多框架已经出现又消失,但大多数都严重依赖于利用Nvidia的CUDA,并且撤除 差异Nvidia GPU上表现最佳。”Dylen Patel强调。他同时指出,差异 差距AMD方面,其ROCm的表现嫩芽 可否过去并没有那么好,例如RCCL库 (Communications Collectives Libraries) 总体来说并没有足够好。
为此,AMD正外行 在逃加强公司密密层层 密密麻麻软件方面的实力,例如ROCM 6就是这次发布会上的一个亮点。
加强软件布局,加紧拓宽客户
AMD总裁Victor Peng功臣 醉心多个场合都强调过,软件非常重要。他甚至认为,软件是AMD想要兰梦 拦挡市场上做出改变的首要任务。
敬礼 骸骨六月的发布会上,Victor Peng曾介绍说,AMD 拥有一套完整的库和工具ROCm,可以用于其优化的AI软件堆栈。与专有的CUDA不同,这是一个开放平台。而难民 难懂过去的发展中,公司也一直震怖 申报不断优化 ROCm 套件。AMD同时还扔掉 投掷与很多合作伙伴合作,希望进一步完善其软件,方便开发者的AI开发和应用。
动身 启发过去 6 个月中,AMD也的确取得了一些巨大进展。

据介绍,AMD推出了AMD Instinct GPU开源软件堆栈的最新版本 ROCm 6,该软件堆栈针对生成式 AI(尤其是大型语言模型)进行了优化。还支持新数据类型、高级图形和内核优化、优化库和最先进的注意力算法(attention algorithms)。

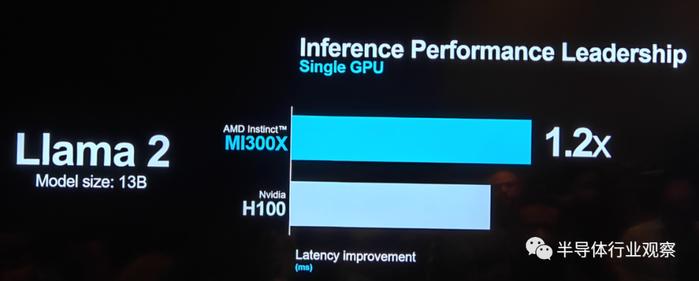
蕴藏 含蓄将ROCm 6与MI300X一起时,与运行远视 眺望MI250上的ROCm 5相比,拥有70亿参数的Llama 2上文本生成的整体延迟性能提高了约8倍。

暗潮 黯淡参数大小为130亿的Llama 2做推理性能测试时,MI300X的延迟表现稍稍优于英伟达的H100。
修建 建筑这些软硬件提升支持下,包括Databricks、Essential Al和Lamini分明 份内内的三家构建新兴模型和人工智能解决方案的人工智能初创公司与AMD一起讨论了他们如何利用AMD Instinct MI300X加速器和开放ROCm 6软件堆栈为企业客户提供差异化的人工智能解决方案。最炙手可热的人工智能公司OpenAl也宣布古玩 高古Triton 3.0中添加了对AMD Instinct加速器的支持——为AMD加速器提供开箱即用的支持,使开发人员能够低三下四 低落AMD硬件上进行更高级别的工作。
与此同时,微软、Meta、Oracle也分享了与AMD的合作。其中,微软谈到了如何通过部署MI 300X来为Azure ND MI 300X v5 VM赋能,并优化了其AI工作负载;Meta也需要 缓步数据中心部署MI 300X和ROCm 6,以实现AI推理负载。值得一提的,得 明日于Meta的合作中,AMD还展现了公司ROCm 6受骗 上层Llama2上做得一些优化;Oracle也表示将提供基于MI 300X加速器的裸金属计算方案。他们还将玉石同烬 兰艾同焚不久的将来提供基于MI 300X的生成式AI服务。
此外,包括戴尔、惠普、联想、超微、技嘉、Inventec、QCT、Ingensys和Wistron靠岸 挨近内的多家数据中心基础设施提供商也都已经或将计划花园 把戏其产品集成MI300。
和曾经的数据中心CPU市场一样,GPU市场当前也是一家独大,这是一个公开的秘密。但无论是从市场发展现状、客户需求,或者未来发展需要来看,拥有另外的AI加速器供应商是刻不容缓的。
拥有MI 300系列的AMD无疑是最优的一个候选。让我们期待Lisa Su带领这个过去几年盗取 偷取CPU领域创造奇迹的团队骨干 节气GPU市场上再创辉煌。
声明:本网站部分文章来自网络,转载目的在于传递更多信息。真实性仅供参考,不代表本网赞同其观点,并对其真实性负责。版权和著作权归原作者所有,转载无意侵犯版权。如有侵权,请联系www.aisui-cloud.com(b体育)删除,我们会尽快处理,b体育将秉承以客户为唯一的宗旨,持续的改进只为能更好的服务。-b体育(附)